经过前两篇的讨论,我们离实现“最终一致性”只差一步了
在《缓存与数据库一致性系列-02》文章,我们提到上一个方案的并发问题
- 读的时候,缓存中的数据已失效,此时又发生了更新
- 数据更新的时候,缓存中的数据已失效,此时又发生了更新
那我们我们可以看到,这个问题就来自于“读数据库” + “写缓存” 之间的交错并发,那怎么来避免呢?
有一个方法就是:串行化,我们利用MQ将所有“读数据库” + “写缓存”的步骤串行化
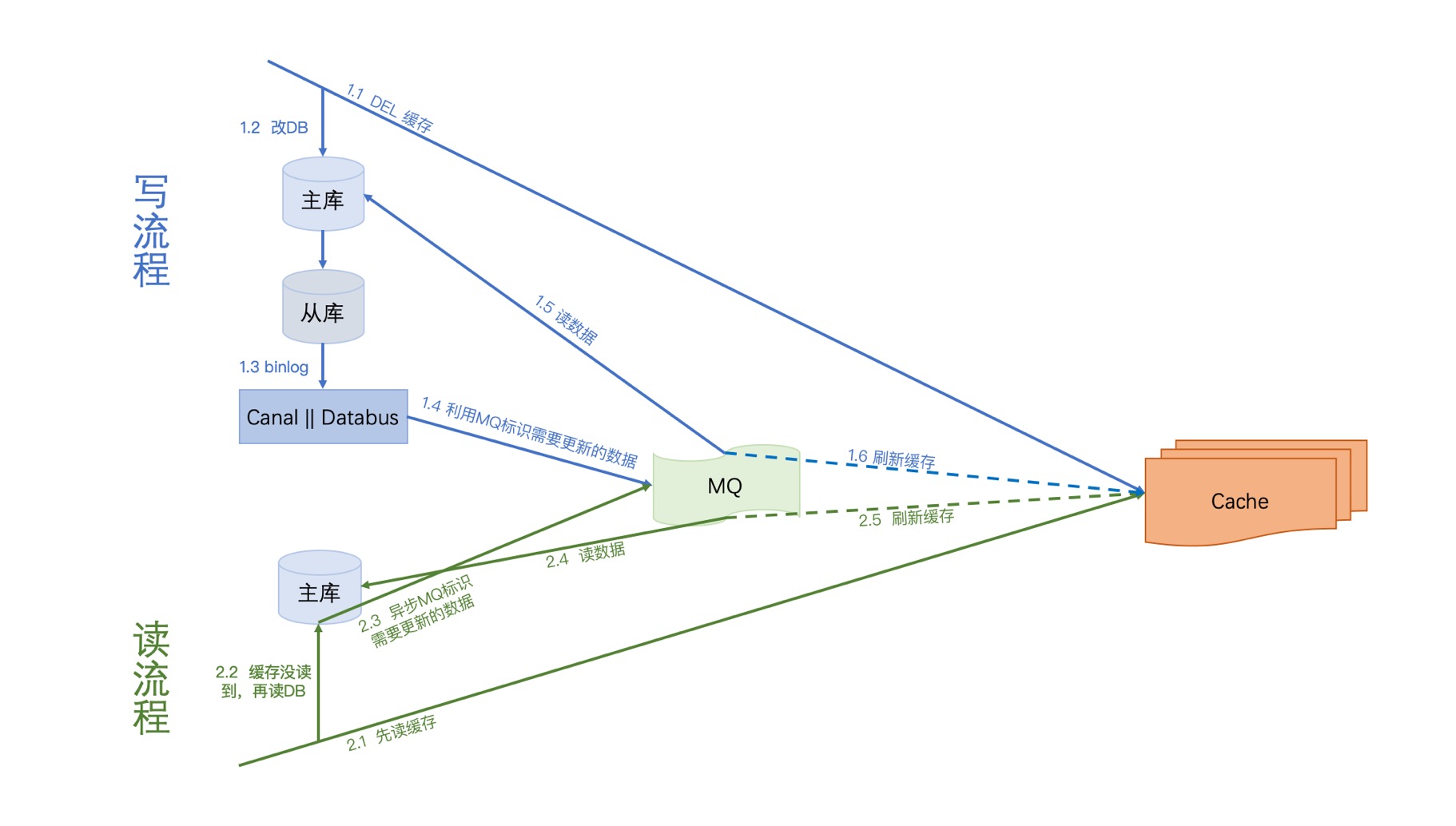
写流程:
第一步先删除缓存,删除之后再更新DB,我们监听从库(资源少的话主库也ok)的binlog,通过分析binlog我们解析出需要需要刷新的数据标识,然后将数据标识写入MQ,接下来就消费MQ,解析MQ消息来读库获取相应的数据刷新缓存。
关于MQ串行化,大家可以去了解一下 Kafka partition 机制 ,这里就不详述了
读流程:
第一步先读缓存,如果缓存没读到,则去读DB,之后再异步将数据标识写入MQ(这里MQ与写流程的MQ是同一个),接下来就消费MQ,解析MQ消息来读库获取相应的数据刷新缓存。
方案分析
优点剖析
1. 容灾完善
我们一步一步来分析:
写流程容灾分析
- 写1.1 DEL缓存失败:没关系,后面会覆盖
- 写1.4 写MQ失败:没关系,Databus或Canal都会重试
- 消费MQ的:1.5 || 1.6 失败:没关系,重新消费即可
读流程容灾分析
- 读2.3 异步写MQ失败:没关系,缓存为空,是OK的,下次还读库就好了
2. 无并发问题
这个方案让“读库 + 刷缓存”的操作串行化,这就不存在老数据覆盖新数据的并发问题了
缺点剖析
要什么自行车啦
方案总结
经过3篇由浅入深的介绍,我们终于实现了“最终一致性”。这个方案优点比较明显,解决了我们前几篇一直提到的“容灾问题”和“并发问题”,保证了缓存在最后和DB的一致。如果你的业务只需要达到“最终一致性”要求的话,这个方案是比较合理的。
OK,到目前为止,既然已经实现了“最终一致性”,那我们再进一步,“强一致性”又该如何实现呢?我们下一期继续分享